Why healthcare leaders must treat supply performance as a clinical responsibility
Patient safety increasingly depends on decisions made outside the clinical floor. When supplies fail to align with patient flow and rising acuity, care teams absorb the risk through substitutions, workarounds, and delayed treatment. These conditions now shape daily operations across healthcare systems, elevating supply chain performance into a defining factor of care quality, safety, and capacity.
Robots & Pencils, an applied AI engineering partner known for high-velocity delivery and measurable business outcomes, today announced the release of Supply Chain as a Patient Safety System, a new thought leadership series written for healthcare executives, clinical leaders, and board members. The series examines how applied AI enables healthcare organizations to anticipate patient demand, respond to real-time acuity shifts, and align resources before operational strain reaches the bedside.
Supply Chain Performance Now Shapes Patient Safety and Care Capacity
Authored by Eric Ujvari, Solutions Lead at Robots & Pencils’ Studio for Generative and Agentic AI, the three-part series reframes supply chain decision-making as a clinical discipline with direct impact on patient outcomes. It challenges legacy models built on historical consumption and static inventory rules, presenting a patient-centered approach grounded in real-world care delivery patterns.
“Healthcare leaders already understand that patient acuity changes hour by hour,” said Ujvari. “What remains under-addressed is the gap between that clinical reality and the systems responsible for positioning supplies. When AI connects patient flow and acuity signals to supply decisions, organizations gain the ability to protect care quality as conditions evolve.”
Why Patient Flow and Acuity Must Drive Supply Decisions
The series unfolds across three core themes that reflect the realities facing modern healthcare systems. The first establishes supply availability as a clinical variable that directly influences safety, treatment timing, and outcomes. The second explains why forecasting must begin with patient flow rather than historical usage to position resources ahead of demand. The third explores how AI-driven, acuity-aware systems transform static inventory into adaptive capacity management that responds to real-time care intensity.
Across each installment, the series draws on current clinical data, operational patterns observed across healthcare environments, and applied AI practices proven in production systems. The result is a practical framework for leaders seeking stronger resilience, clearer governance insight, and greater alignment between operational decisions and patient safety outcomes.
How Applied AI Aligns Supply Decisions with Clinical Reality
This release reflects Robots & Pencils’ broader focus on building applied AI systems that operate at enterprise scale and deliver measurable impact. The firm partners with healthcare organizations to design intelligent platforms that integrate clinical signals with operational execution, supporting safer care delivery in complex and dynamic environments.
Healthcare leaders are encouraged to read the full series and engage with a perspective that positions supply performance as a foundational pillar of patient safety.
Healthcare moves forward when systems anticipate patients, align resources, and protect care before strain appears.
Patient flow forecasting positions supply ahead of scheduled demand. Then reality intervenes. The stable post-surgical patient decompensates overnight. The routine knee replacement encounters unexpected blood loss, consuming supplies planned for three procedures. Emergency volumes spike when a multi-vehicle accident fills every trauma bay.
Patient acuity shifts constantly, and those shifts drive supply needs more powerfully than any schedule.
When Static Rules Meet Dynamic Reality
Most healthcare inventory operates on fixed replenishment rules designed for typical census and standard acuity. When patient mix changes, those par levels become instantly obsolete. Healthcare supply chains often operate in silos, with fragmented systems that lack integration and standardization, hindering communication and leading to inefficiencies and difficulties in tracking and managing inventory. When surgical runs critically low on a wound care product sitting unused two floors up in the ICU, nobody knows. Supply teams discover shortages only after nurses call, “We’re out, we need it now!”
This happens against rising clinical intensity. Emergency departments report critically ill patients requiring immediate, resource-intensive care increasing 6% year-over-year. Inventory systems still calculate needs based on yesterday’s patient population, not today’s sicker, more complex cases.
The Clinical Awareness Gap
Clinicians recognize when patients are deteriorating, when case complexity is rising, and when unit intensity is increasing. Their judgment guides countless decisions, such as calling for additional equipment, requesting backup supplies, and positioning resources near high-acuity patients.
Supply systems see none of this because traditional healthcare inventory management waits for supplies to be used before triggering reorders, creating a lag between when clinicians recognize the need and when the system responds. Research indicates that 74% of healthcare professionals have observed supply shortages compromising care quality in high-acuity environments. The adaptation burden falls on clinical teams who maintain patient safety despite inventory systems that cannot respond to real-time changes in care intensity.
AI Enables Acuity-Aware Inventory
Modern electronic health records contain continuous acuity indicators, such as vital sign trends, lab values, and medication patterns. AI systems monitor these signals across health systems, translating what clinicians already recognize into system-wide projections that move faster than manual coordination ever could. As a patient deteriorates or overall unit acuity rises, the model updates projected supply needs for that patient, that unit, and connected departments before current inventory depletes. Supply teams receive alerts about emerging shortages while time remains to respond.
This real-time monitoring works in tandem with predictive forecasting. By analyzing historical patient data, disease trends, and seasonal patterns, AI establishes baseline demand expectations. When real-time acuity signals diverge from those baselines, the system recalibrates. The combination helps healthcare organizations optimize inventory levels, reduce stockouts, and minimize excess inventory.
From Inventory to Capacity Management
Acuity-aware inventory reveals a clinical reality. Supply availability defines care capacity. Traditional measures track inventory turns and fill rates. Acuity-aware systems measure care capacity, asking, “Can this unit safely accept another high-acuity patient given current supply levels?”
AI-driven decision support systems assist hospital administrators in making informed choices regarding resource utilization, inventory management, and workflow efficiency, contributing significantly to cost savings and ensuring judicious resource allocation.
When inventory responds to patient acuity in real time, supply chains function as orchestration layers that align resources across units early, supporting care delivery before operational strain emerges.
The defining difference is real-time alignment. When supply systems adapt as quickly as clinical reality changes, patient safety becomes resilient and dependable. Leaders interested in exploring how this level of alignment can be designed into their operations are encouraged to continue the conversation.
Key Takeaways
Patient acuity drives supply needs more powerfully than any schedule. As patient condition changes, resource requirements shift immediately, often hours before consumption patterns reveal the change.
Static inventory rules lose effectiveness as patient mix changes. Par levels designed for typical acuity become obsolete when sicker patients arrive, yet traditional systems cannot recognize or respond to these shifts.
Clinicians experience shortages before supply systems register them. Manual replenishment and limited real-time visibility create gaps where clinical teams adapt to shortages long before procurement recognizes the problem.
AI enables real-time acuity-aware inventory management. Machine learning algorithms monitor patient condition indicators across health systems, translating clinical signals into supply projections faster than manual processes.
Acuity-aware systems transform supply chains into capacity management tools. When inventory aligns with real-time patient acuity, care quality remains stable regardless of census or complexity fluctuations.
FAQs
How does patient acuity affect healthcare supply needs? Patient acuity directly determines supply consumption rates and resource types required. Higher-acuity patients need more intensive monitoring equipment, specialized medications, advanced wound care supplies, and infection control resources. When patient acuity rises unexpectedly, supply needs increase dramatically and immediately, often exceeding static inventory levels designed for average census and typical complexity.
What is acuity-aware inventory management in healthcare? Acuity-aware inventory management uses real-time patient condition data to adjust supply positioning and replenishment decisions. Instead of maintaining fixed par levels based on historical averages, the system continuously monitors acuity indicators across all patients and dynamically updates projected supply needs. This enables anticipatory replenishment before shortages occur during high-acuity periods.
Why do traditional healthcare inventory systems struggle during acuity surges? Traditional healthcare inventory systems rely on manual tracking and reactive replenishment, typically responding only after consumption patterns reveal shortages. When patient acuity surges, supply needs spike immediately while consumption data lags by hours or days. Manual processes cannot detect or respond quickly enough, forcing clinical teams to improvise workarounds that introduce variation and safety risks into care delivery.
How can AI improve healthcare supply chain responsiveness to patient needs? AI algorithms continuously analyze electronic health record data to detect changes in patient condition, treatment intensity, and care complexity. The system recognizes acuity patterns associated with specific supply requirements and projects for emerging needs before current inventory depletes. This enables proactive positioning of resources during high-acuity periods, reducing stockouts while minimizing excess inventory and waste.
Most healthcare supply forecasting still operates on retail logic. Organizations analyze historical purchase data, calculate reorder points based on consumption patterns, and set safety stock levels to buffer against variability.
Then flu season hits and hospital admissions nearly double week over week, jumping from 9,944 to 19,053 patients as they did in December 2025. Supply teams scramble to explain why inventory models built on previous usage failed to anticipate this quarter’s need.
The answer reveals a fundamental insight: healthcare demand follows patients, not consumption history. The most sophisticated consumption forecasting model will always lag clinical reality because it measures what already happened rather than what comes next.
Why Consumption Data Creates a Structural Lag
Healthcare operates differently than retail. Retail demand follows relatively stable patterns with seasonal variation. Healthcare experiences baseline instability shaped by events, such as disease outbreaks, weather patterns, and trauma incidents that drive volume fluctuations. Acuity levels shift when sicker patients present or surgeries prove more complex than anticipated.
The Echo Effect in Supply Chain Data
These dynamics create clinical demand before they appear in consumption data. By the time usage patterns reveal a shortage, clinical teams have already adapted through substitutions or workarounds. Organizations end up measuring the adaptation rather than the original need.
This reveals where the leverage lies. Investment in consumption analytics optimizes efficiency around a lagging signal. Investment in patient flow analytics positions resources ahead of clinical need.
Patient Flow Offers Forward Visibility
Patient flow data provides what consumption history cannot: advance signals of clinical demand. Scheduled appointments, procedure bookings, and patient registrations indicate incoming volume across care settings. Diagnostic codes and acuity scores reveal care intensity requirements. Expected procedure duration or length-of-stay predicts resource needs over time.
The distinction matters. Consumption forecasting asks, “What did patients use?” Patient flow forecasting asks, “What will patients need?”
How Machine Learning Enables Patient-Centered Forecasting
When emergency volumes spike or outpatient schedules intensify, the model recalculates supply requirements. When procedures get rescheduled, inventory projections adjust in real time. When case complexity increases, the system alerts procurement teams to position additional capacity.
Building Anticipatory Supply Capacity
Patient flow forecasting transforms inventory management from reactive replenishment to anticipatory positioning. Over time, these systems learn from repeated care patterns across units, seasons, and service lines, allowing organizations to reuse insight rather than rebuild forecasts from scratch.
Organizations reduce waste by ordering based on predicted patient needs rather than generic safety stock formulas. Expired inventory decreases when supplies arrive aligned with actual clinical demand. Supply availability scales with care capacity. When census rises, resources adjust accordingly.
Reframing Supply Chain Performance
This shift requires measuring different outcomes. Traditional supply chain metrics focus on procurement efficiency, such as cost per unit, inventory turns, and fill rates. Patient-centered forecasting demands alignment metrics, such as supply availability at time of clinical need, forecast accuracy relative to patient volume, and inventory positioning matched to care intensity across settings.
From Cost Optimization to Care Enablement
The critical question shifts: Were the right supplies available when clinical teams needed them? Success gets measured against patient admission patterns rather than past consumption cycles. This transformation reframes supply chain performance from cost optimization to care enablement.
Healthcare organizations already possess the clinical data required for patient flow forecasting. Electronic health records contain scheduling information, diagnosis codes, and acuity assessments. The opportunity lies in connecting this clinical intelligence to supply chain systems.
The Next Evolution in Healthcare Supply Chain Management
Healthcare has always understood that patients drive demand. The analytics now exist to make that understanding operational. When supply plans begin with patient volume, care complexity, and treatment schedules, the supply chain becomes what it should be: a patient safety system designed to ensure the right resources exist precisely when clinical teams need them.
Organizations that adopt patient-centered forecasting build supply systems that support clinical operations proactively rather than react to them retrospectively. That transformation, from trailing indicator to leading system, defines the future of healthcare supply chain management.
Patient flow forecasting positions supplies ahead of demand. But what happens when a stable patient deteriorates overnight? When emergency volumes spike unexpectedly? When procedure complexity exceeds projections? Part 3 explores how real-time acuity data transforms static inventory into adaptive systems that respond to clinical reality as it unfolds.
Organizations that succeed treat forecasting as a capability rather than a project. Leaders interested in designing forecasting systems that learn from each cycle of care delivery and compound value over time are encouraged to continue the conversation.
____________________________
Key Takeaways
Healthcare demand follows patients, not purchase history. Traditional forecasting models measure what already happened. Patient encounters drive supply needs before consumption data registers the demand.
Patient flow data reveals demand before it occurs. Scheduled appointments and procedure bookings predict requirements in advance, enabling proactive positioning rather than reactive replenishment.
Machine learning converts clinical signals into supply forecasts. Analytics platforms integrate scheduling data with treatment patterns to predict volume and intensity, updating as conditions change.
Patient-centered forecasting transforms supply chains into care enablement systems. When projections follow patient flow, organizations position resources ahead of clinical need rather than trailing behind it.
FAQs
What is patient flow forecasting in healthcare supply chain management? Patient flow forecasting uses clinical data, such as admissions, acuity scores, diagnostic codes, and treatment pathways, to predict supply needs based on incoming patient populations rather than historical consumption patterns. This approach provides earlier demand signals and more accurate resource projections than traditional inventory models.
Why do traditional supply forecasting methods fail in healthcare settings? Traditional forecasting assumes stable demand with predictable variation. Healthcare faces event-driven volatility where patient admissions, acuity levels, and treatment complexity shift rapidly. Consumption-based models reveal shortages only after they’ve disrupted care, while patient flow forecasting anticipates demand before patients arrive.
How does patient flow forecasting improve patient safety? When supply forecasting follows patient demand, necessary resources are available when clinical teams need them. This reduces workarounds, substitutions, and treatment delays caused by shortages. Standardized protocols remain intact, cognitive load on clinicians decreases, and care quality improves when supply availability aligns predictably with clinical needs.
Every clinical delay tells a story most health systems never capture. When operating rooms postpone procedures because endotracheal tubes are unavailable, when chemotherapy schedules shift due to drug shortages, or when critical equipment sits idle awaiting replacement parts, organizations meticulously document the operational disruption. What they rarely measure is the clinical cost: the patient whose condition worsens during the delay, the medication substitution that triggers an adverse reaction, the equipment workaround that introduces error into an otherwise routine protocol.
In healthcare, supply availability directly influences patient safety, treatment timing, and clinical outcomes. Until supply chain decisions are treated as patient safety decisions, health systems will underestimate their true clinical risk. The traditional view treats the supply chain as an operational infrastructure. If supplies arrive on time, care proceeds as planned. But supply availability functions as an unacknowledged clinical variable. Patient outcomes depend not just on diagnostic accuracy and treatment selection, but on whether the right resources exist when needed.
Healthcare Supply Shortages are Now a Patient Safety Crisis
Supply chain disruptions have moved from occasional inconvenience to persistent clinical threat across the full spectrum of medical resources. According to 2023 research, 60% of healthcare professionals reported shortages affecting drugs, single-use supplies, or medical devices, with 74% noting these shortages compromised care quality in surgery and anesthetics. Healthcare teams responded by rationing supplies, with 86% admitting they restricted drugs, supplies, or equipment in short supply. The clinical consequences were immediate. Nearly half reported that supply shortages had delayed patient treatment, and one in four clinicians witnessed medical errors directly linked to shortages.
The problem has intensified rather than resolved. By July 2024, federal data documented 140 ongoing drug shortages alongside shortages of critical medical devices, including IV bags, cardiac diagnostics, and oxygenators. The situation has only intensified. As of the first quarter of 2025, 270 drugs remained on active shortage lists, with nearly 60% of shortages persisting for two or more years. Add to this the reality that 70% of medical devices and more than 80% of active pharmaceutical ingredients marketed in the U.S. are manufactured exclusively overseas, and the vulnerability becomes clear. These shortages increasingly impact hospitals, health systems, and outpatient care settings across the United States. Supply availability has become a patient safety issue with global dependencies.
When Cost Metrics Replace Clinical Measurement
Healthcare organizations track supply chain performance religiously, but they’re measuring the wrong things. Financial dashboards light up with procurement costs, inventory carrying expenses, and contract compliance rates. What’s missing is the clinical measurement: How did that three-week backorder affect patient outcomes? What happened to care quality when clinicians worked around shortages with unfamiliar substitutes?
The financial burden is substantial. Supply costs represent 30 to 40% of a typical health system’s cost base, making them one of the largest expense categories after labor. In 2024 alone, total hospital expenses grew 5.1%, significantly outpacing the overall inflation rate of 2.9%.
Yet even these figures capture only operational costs, not clinical consequences. Perhaps most telling: 94% of healthcare administrators now expect to delay critical equipment upgrades to manage rising supply chain costs, while 90% of supply chain professionals anticipate continued procurement disruptions. These are projections about care delivery capacity and the ability to provide treatments when patients need them.
From Support Function to Patient Safety System
Medical supply chains in hospitals and health systems differ fundamentally from other institutional infrastructure. When an HVAC system fails, patient care continues while facilities teams fix it. When a shortage forces clinicians to use unfamiliar equipment or substitute medications, the workaround becomes part of the care delivery itself. The supply chain supports clinical work and shapes it.
This matters because healthcare has spent decades perfecting standardized clinical protocols designed to minimize variation and reduce errors. Shortages force the exact opposite: variation, improvisation, and increased cognitive load as clinicians navigate unfamiliar alternatives. The irony is profound. Organizations invest heavily in clinical standardization while accepting supply instability that undermines those very standards.
The gap lies in measurement philosophy. Organizations track supply chain performance as a cost center and track patient outcomes as a quality metric. Most analytics systems miss the connection between the two entirely.
Building Measurement Systems That Connect Supply to Patient Safety
Closing this gap requires integrating supply chain data with clinical outcomes in ways that reveal causal relationships, not just correlations. Which shortages are associated with longer procedure times? Where do substitutions correlate with increased complications? When do inventory gaps predict care delays? These questions define a new category of healthcare analytics focused on linking supply chain data to patient safety outcomes.
Decision-grade analytics systems now make these questions answerable at scale. When supply chain data and clinical outcomes are connected through calibrated intelligence, patterns emerge that human observers cannot detect, linking supply disruptions to patient safety outcomes across thousands of encounters. The barrier is not technical capability but system design. When supply chain and clinical quality operate in separate measurement universes, organizations miss the causal signals that indicate emerging patient safety risk.
Treating supply availability as a clinical variable requires measuring it accordingly. But measurement alone does not prevent shortages. How do organizations position supplies ahead of need rather than react to depletion? The answer lies in forecasting clinical demand based on patient admissions, acuity levels, and discharge patterns. Part 2 of our series explores why effective forecasting begins with patients first, then products. Read it now.
Transforming supply chains into patient safety systems requires intelligence that learns, recalibrates, and improves as care conditions evolve. Organizations exploring how to design operational systems that mature safely over time are encouraged to continue the conversation.
Key Takeaways
Supply availability functions as a clinical variable. When drugs, devices, or equipment are unavailable, patient safety, treatment timing, and outcomes shift in measurable ways.
Healthcare supply shortages introduce clinical risk, not just operational disruption. Delays, substitutions, and workarounds increase variation in care and elevate the likelihood of errors.
Connecting supply chain data to patient outcomes transforms the supply chain into a patient safety system. Health systems that measure this relationship gain earlier, decision-ready warning signals and stronger clinical resilience.
FAQs
How do healthcare supply shortages affect patient outcomes? Healthcare supply shortages affect patient outcomes by delaying treatment, forcing medication substitutions, and increasing clinical variation. These disruptions raise the risk of adverse events, procedural complications, and care quality degradation, particularly in high-acuity settings such as surgery, oncology, and critical care.
Why is healthcare supply chain management a patient safety issue? Healthcare supply chain management is a patient safety issue because supply availability directly shapes how care is delivered. When clinicians must work around shortages using unfamiliar equipment or alternative therapies, cognitive load increases and standardized protocols break down, elevating the risk of errors.
How can health systems measure the clinical impact of supply shortages? Health systems can measure the clinical impact of supply shortages by integrating supply chain data with clinical outcomes. This includes tracking treatment delays, substitution rates, complication trends, and procedure duration changes associated with inventory gaps. Advanced analytics can surface patterns that traditional operational dashboards miss.
What is the future of healthcare supply chain management? The future of healthcare supply chain management centers on forecasting clinical demand based on patient admissions, acuity, and care pathways. By planning supply availability around patient needs rather than procurement cycles, health systems strengthen care reliability and protect patient safety.
Robots & Pencils Achieves Amazon Web Services (AWS) Advanced Tier Partner Status
Robots & Pencils
Milestone reinforces Robots & Pencils’ strength in building and operating cloud-native and AI-enabled systems on AWS
Robots & Pencils, an applied AI engineering partner known for high-velocity delivery and measurable business outcomes, today announced it has achieved AWS Advanced Tier Partner status. The designation marks a significant milestone in the company’s continued growth, delivering production-grade systems on AWS for enterprise organizations.
AWS Advanced Tier Recognition Reflects Production-grade Delivery at Enterprise Scale
AWS Advanced Tier Partner status recognizes organizations with demonstrated depth in AWS delivery, technical expertise, and customer success at scale. Partners at this level consistently design, build, and operate secure, resilient, and scalable systems running in production. Robots & Pencils earned this designation through sustained enterprise delivery, a strong bench of AWS-certified engineers, and real-world workloads running on AWS.
A High-Velocity Alternative to Traditional Global Systems Integrators
Robots & Pencils operates as a nimble alternative to traditional global systems integrators, pairing AWS-native architecture with a relentless focus on velocity and impact. Small, senior, highly focused teams move quickly from idea to execution, delivering production-ready systems that create value early and improve continuously through real-world learning.
“Our AWS Advanced Tier designation continues to build on strong momentum as we strengthen our relationship with AWS,” said Len Pagon Jr., Chief Executive Officer of Robots & Pencils. “In December, we were selected as one of 11 AWS Partners out of more than 190,000 to join the new Pattern Partner program. In January, we launched our Bellevue, WA Innovation Center next door to AWS HQ to work closely with the AWS GenAIIC team. Now, as an AWS Advanced Tier Services Partner, we have access to additional AWS funding for proofs of concept and substantial resources to support our clients.”
Building and Operating Generative and Agentic AI Systems that Scale
Enterprise leaders continue accelerating modernization and AI initiatives that demand speed, reliability, and operational maturity.
AWS Advanced Tier status signals that Robots & Pencils brings disciplined execution and rapid iteration to move confidently from strategy to production and scale. Clients gain earlier insight, reduced delivery risk, and steady progress aligned to clear business outcomes.
“Enterprises are moving quickly toward generative and agentic AI systems that operate as an enablement layer of their business,” said Jeff Kirk, Executive Vice President of Applied AI at Robots & Pencils. “AWS provides a powerful foundation, and our role is to design and deliver AI systems that integrate securely, perform reliably, and scale with confidence. Advanced Tier recognition affirms our ability to move AI from ambition into production.”
Certified Talent and Engineering Discipline Behind AWS Advanced Tier Recognition
The AWS Advanced Tier recognition also reflects the company’s investment in certified talent, security discipline, and operational excellence.
“AWS Advanced Tier status is earned through consistency, accountability, and a deep commitment to craft,” said Nicholas Waynik, Vice President of Engineering at Robots & Pencils. “Our engineers invested the time to master the platform, earn the certifications, and apply that knowledge to systems running in production. This recognition reflects the standards they hold themselves to every day and the trust our clients place in their work.”
Enterprise-ready AI Architectures Delivering Impact Across Industries
Robots & Pencils also holds AWS Pattern Partner recognition, highlighting its strength in delivering repeatable, enterprise-ready architectures for applied AI and intelligent systems. This capability complements Advanced Tier status by reinforcing architectural leadership alongside delivery maturity, while maintaining a clear focus on execution that performs in production.
Robots & Pencils delivers application modernization, cloud-native product development, data platforms, and AI-enabled systems on AWS across Consumer Products and Retail, Education, Energy, Financial Services, Healthcare, and Manufacturing. These solutions support regulated environments, high-growth digital products, and complex enterprise ecosystems where reliability and scalability matter every day.
Request an AI briefing to evaluate how applied AI can deliver velocity and impact within your organization.
Your Churn Model Works Perfectly. So Why are Your Customers Still Leaving?
Rushi Pol
There’s a pattern that keeps showing up in retail AI projects. A data science team spends months building a churn prediction model. They tune it, validate it, and present impressive accuracy metrics to leadership. The model goes into production. And six months later, when someone asks what happened to the churn rate, the uncomfortable answer is, “Nothing changed.”
The model works. It predicts churn beautifully. It just doesn’t prevent it.
This might seem like an implementation problem. Maybe the marketing team didn’t act on the predictions quickly enough, or the retention offers weren’t compelling enough. But the issue runs deeper than that. The problem starts with how the project was framed in the first place.
When Churn Prediction Becomes Theater
Here’s what prediction theater looks like in practice: Your churn model flags a high-risk customer on Monday morning. The prediction appears in a dashboard. Someone from marketing reviews it during Thursday’s retention meeting and adds the customer to next week’s email campaign. The customer cancels their subscription on Tuesday. Five days after the model predicted it. Three days before marketing acted on it. The model performed perfectly. It predicted an outcome. But prediction without intervention is just expensive surveillance.
This pattern repeats because organizations optimize for the wrong outcome: prediction accuracy instead of churn reduction. Accuracy is measurable, improvable, and requires no workflow changes. You can plot ROC curves and present F1 scores in quarterly reviews. Prevention requires rebuilding operations across marketing automation, customer service systems, and approval workflows.
Why Accurate Churn Prediction Rarely Changes Outcomes
The constraint is intervention capacity, not model accuracy. Improving your model from 85% to 87% accuracy doesn’t mean anything if you can only act on 20% of the predictions. When intervention capacity is the bottleneck, marginal accuracy improvements deliver zero business value. It’s like building a faster fire alarm when what you actually need is a sprinkler system. For many retailers, the real constraint shows up in the approval process. Attractive retention offers often require VP sign-off, which can introduce multi-day delays and make timely intervention difficult.
Prevention requires event-driven architecture, where systems respond immediately to customer actions within seconds or minutes instead of waiting for batch processing cycles that run nightly or weekly. When a customer shows churn signals like cart abandonment, a subscription cancellation attempt, or declining engagement, the system must detect the signal, assess the situation, and intervene automatically while the customer is still engaged. This is a very different approach from prediction systems that generate reports for human review.
The Architecture of Churn Prevention
Netflix offers one of the most familiar examples of what prevention architecture looks like in practice. Looking at how their system works makes the four components of effective prevention clear.
Signal detection: The system continuously monitors viewing behaviors, like declining watch time, increased browsing without watching, and longer gaps between sessions. These signals indicate churn risk before the customer consciously decides to cancel.
Intelligence layer: When signals trigger, the system calculates subscriber lifetime value, checks recent engagement patterns, and determines if intervention is warranted. Not every signal gets an intervention. The system only acts when the data suggests it will work.
Automated intervention: Within seconds, the recommendation engine adjusts what content appears, emphasizing shows with high completion rates for similar subscribers. This happens without dashboard review or marketing approval, allowing the system to act while the customer is still engaged.
Outcome measurement: The system tracks whether the interventions worked. Did the subscriber watch the recommended content? Did engagement increase? The algorithm continuously learns which recommendations retain which subscriber segments.
This automated prevention architecture contributes to Netflix maintaining an industry-leading monthly churn rate hovering between 1-3% over the past two years, well below the streaming industry average of approximately 5%. Over 80% of content watched on Netflix comes from these algorithmic recommendations. The distinction is critical: Netflix built a model to predict which subscribers might leave and the systems that automatically present compelling reasons to stay at the moment of decision.
This same prevention architecture applies just as effectively to physical products. Customer signals still appear in real time through behaviors like cancellation attempts, delayed reorders, or changes in purchase patterns. Systems can evaluate context such as purchase history and customer value, decide whether intervention makes sense, and respond immediately with relevant offers, guidance, or incentives. By measuring outcomes and learning which responses work for different customers, physical product businesses can intervene at the moment decisions are forming rather than after churn has already occurred.
What Makes Churn Prevention Smart
Problems emerge when components are skipped. A subscription box retailer might implement automated cancellation prevention while leaving out the intelligence layer, the business logic that prevents gaming. Without assessing customer value, limiting offer frequency, or recognizing behavior patterns, every customer who clicks ‘cancel’ receives the same discount. The system works on the surface, but over time it teaches customers how to exploit it. What started as a retention tactic turns into a habit, margins erode, and prevention stops doing the work it was meant to do.
This gaming scenario raises the immediate question marketing teams ask: “Doesn’t automation mean losing brand control?” Not if the intelligence layer encodes your judgment as guardrails. No discount over XX%. No offers conflicting with active campaigns. VIP customers (top X% LTV) escalate to human review before any automated intervention. Win-back offers only after a defined cooling period. Your brand standards become executable rules that prevent the system from going rogue, while still acting faster than manual review workflows.
Operational Readiness Comes Before Modeling Sophistication
Before building a churn model, map the complete intervention workflow:
How will predictions trigger actions across channels? (If the answer involves a weekly dashboard review, you’re building a prediction theater.)
What systems enable real-time personalization? (Can you respond when customers show churn signals?)
Who has the authority to modify customer treatment dynamically? (Automated systems with guardrails, or manual approval workflows?
What is the acceptable latency between prediction and intervention? (Minutes? Hours? Days?)
Clear answers to these questions determine readiness. Building prediction models without intervention infrastructure creates sophisticated systems that generate insights teams cannot act on at retail speed.
Building AI Systems That Act Before Customers Leave
The goal is simple. Prevent customers from leaving in the moment when they are making that decision.
The shift from prediction to prevention requires AI-powered systems that can detect signals, assess customer value, and execute personalized interventions automatically and without human review delays. This works when you encode human judgment into systems that can act at machine speed. The intelligence layer (LTV assessment, discount frequency limits, pattern detection, and margin guardrails) separates effective prevention from expensive automation theater.
Here’s how to start:
Step 1: Choose one high-value churn segment (not the largest, but the one where retention has the highest dollar impact).
Step 2: Map signal to intervention: Document every step from customer signal to executed action. Where does latency creep in?
Step 3: Cut one manual approval step. If every offer needs manual sign‑off, you eliminate any chance of quick action. Let AI automate and accelerate that step.
Step 4: Measure what matters: Track retention rates and customer lifetime value, not model accuracy.
The technical challenge of predicting churn is no longer the constraint. Durable advantage now comes from leaders who design organizations that act, decisively and automatically, at the moment of customer decision.
The pace of AI change can feel relentless with tools, processes, and practices evolving almost weekly. We help organizations navigate this landscape with clarity, balancing experimentation with governance, and turning AI’s potential into practical, measurable outcomes. If you’re looking to explore how AI can work inside your organization—not just in theory, but in practice—we’d love to be a partner in that journey.Request an AI briefing.
Key Takeaways
Architecture determines outcomes. Event-driven systems enable real-time intervention, while batch systems document churn after it happens.
Intervention capacity creates the true bottleneck. Automated prevention systems scale decision-making with the customer base.
The intelligence layer makes prevention smart. LTV assessment, discount limits, and margin guardrails prevent gaming while maintaining brand control.
FAQ
What’s the difference between churn prediction and churn prevention? Churn prediction identifies which customers may leave. Churn prevention intervenes automatically to change customer behavior before they leave. Prediction relies on analytics. Prevention relies on decision automation and real-time execution.
Why do accurate churn models fail to reduce churn rates? Prediction accuracy creates no value without intervention capacity. When models identify more at-risk customers than teams can act on, marginal accuracy delivers zero impact.
What makes a churn prevention system different architecturally? Prevention systems use event-driven architectures that automate the full loop: signal detection, intervention selection, execution, and outcome measurement.
How should retail organizations measure churn AI success? Track retention improvement, customer lifetime value growth, intervention response rates, and cost per retained customer. Model accuracy measures technical quality. Business impact requires retention metrics.
Context Engineering is the Part of RAG Everyone Skips
Nilesh Patwardhan
This moment is familiar. A “simple” policy question comes up, and the conversation slows to a halt. Not because the answer is unknowable, but because it’s buried somewhere in a 100-page PDF, inside a binder no one wants to open, on an intranet that technically exists but rarely helps when it matters.
Under time pressure, people do what people always do. They ask around. They rely on memory. They make the best call they can with what they recall.
That’s the situation many organizations quietly operate in. Field teams losing meaningful time every shift just trying to locate procedures. Compliance leaders increasingly uneasy with how often answers came from tribal knowledge. The documents exists. Access technically exists. What’s missing is usable context.
When Policy Knowledge Exists but Usable Context Does Not
The obvious move is to build a RAG (Retrieval-Augmented Generation) assistant.
That’s where the real work begins.
What we didn’t fully appreciate at first was that this wasn’t a retrieval problem. It was a context construction problem.
The challenge wasn’t finding relevant text. It was deciding what the model should be allowed to see together. In hindsight, this had less to do with RAG mechanics and more to do with what we’ve come to think of as context engineering: deliberately designing the context window so the model sees complete, coherent meaning instead of fragments.
Where the “Obvious” Solution Fell Short
We didn’t start naïvely. We explored modern RAG patterns explicitly designed to reduce context loss. Parent–child retrieval, hierarchical and semantic chunking, overlap tuning, and filtered search strategies. These approaches are widely used in production for structured documents, and for good reason.
They did perform better than baseline setups.
But for these policy documents, the same failure mode kept showing up.
Answers were fluent. Confident. Often almost right.
Procedures came back incomplete. Steps appeared out of order. Exact wording, phone numbers, escalation paths, timelines – softened or blurred. And when the model couldn’t see the missing context, it filled the gaps with something plausible.
Why “Almost Right” Answers Are Dangerous in Compliance & Procedural Work
At that point, the issue was no longer retrieval quality.
It was context loss at decision time.
A procedure isn’t just information. It’s a sequence with dependencies. Even when parent documents were pulled in after similarity-based retrieval, the choice of which parent to load was still probabilistic, driven by embedding similarity rather than document structure.
In compliance-heavy environments, “coherent but incomplete” is an uncomfortable place to land.
This became the line we couldn’t ignore:
Chunking isn’t a neutral technical step. It’s a design decision about what context you’re willing to lose and when.
Chunking Is a Design Choice About Risk
Most modern RAG systems correctly recognize that context matters. Parent–child retrieval and hierarchical chunking exist precisely because naïve fragmentation breaks meaning.
What many of these systems still assume, though, is that similarity-first retrieval should remain the primary organizing principle.
For many domains, that’s a reasonable default. For large policy documents, it turned out to be the limiting factor.
Policy documents reflect how institutions think about responsibility and risk. They’re organized categorically. They use deliberate, constrained language like – within 24 hours, contact this number. And their most important procedures often span pages, not paragraphs.
When that structure gets flattened into ranked results, even if parent sections are expanded later – similarity still decides which context the model sees first.
And when surrounding context disappears, the model does what it’s trained to do: it narrates.
Not recklessly. Not maliciously.
Just helpfully.
That was the subtle failure mode we kept encountering – the system becoming a confident narrator when what the situation required was a careful witness.
Naming the Problem Changed the System
Once we framed this as a context engineering problem, the architecture shifted.
Instead of asking, “How do we retrieve the most relevant chunks?” we started asking a different question:
What does the model actually need to see to answer this safely and faithfully?
That reframing moved us away from similarity-first defaults and toward deliberate context construction.
In retrospect, this wasn’t a rejection of modern RAG techniques. It was a refinement of them.
The Design Decisions That Actually Changed Outcomes
Once the problem was named clearly, a small set of design decisions emerged as disproportionately impactful. None of these ideas are novel on their own. What mattered was how they were combined.
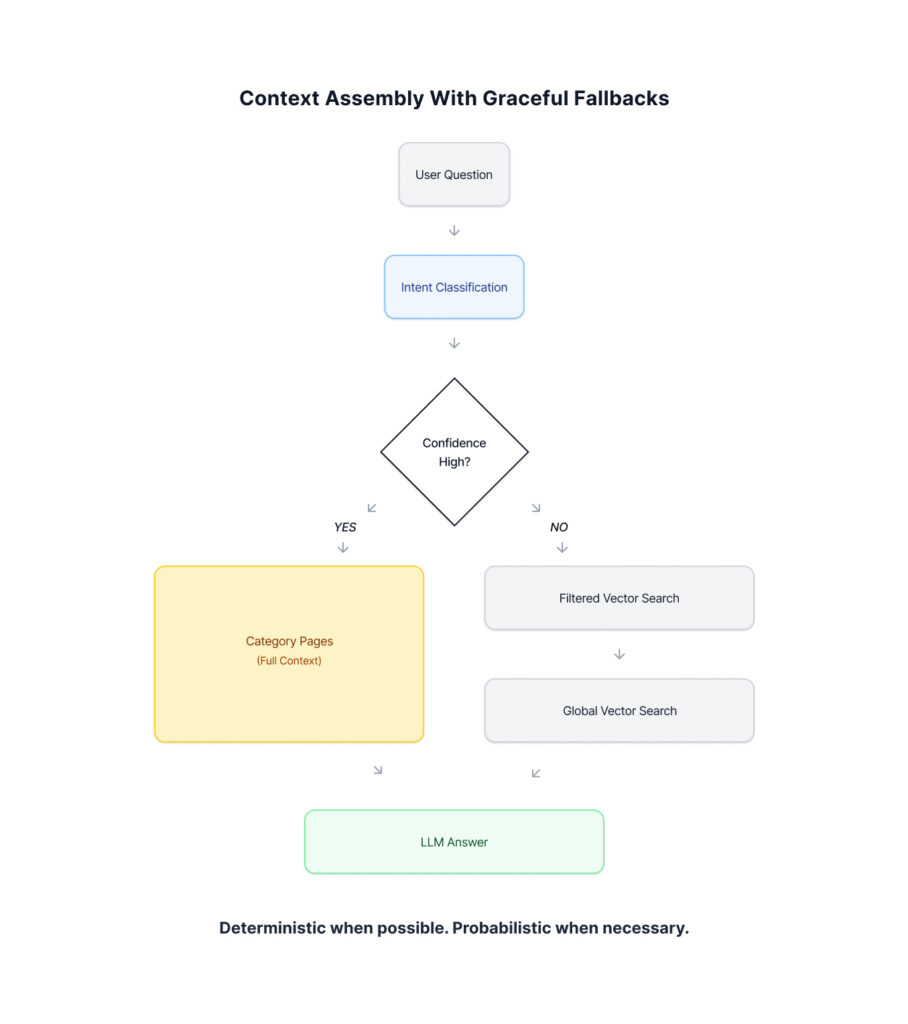
Classify First, Then Retrieve
Before touching the vector store, the system classifies what the user is asking about. An LLM determines the query category and confidence level.
When confidence is high, full pages from that category are loaded via metadata lookup – no embedding search required.
When confidence is low, the system falls back to chunk-based vector search, not as the default, but as a safety net for ambiguous or cross-cutting questions.
You can think of this as parent–child retrieval where the parent is selected deterministically by intent, rather than probabilistically by similarity.
Dual Document Architecture
Location-specific documents were separated from company-wide documents, each with its own taxonomy. “What’s the overtime policy?” and “Where’s the emergency exit?” require fundamentally different context.
Domain-Specific Taxonomy
Categories were designed to align with how policy documents are actually authored, not how users phrase questions. Categories were assigned at upload time, not query time, making retrieval deterministic and fast.
Token-Aware Page Loading
Even full pages can exceed context limits. Dynamic loading prioritizes contiguous pages and stops when the token budget is reached. The tradeoff was intentional: complete procedures beat partial matches.
The Big Lesson: Context Is the Real Interface Between Policy and AI Judgment
Context is easy to treat as plumbing – important, but invisible.
In reality, context is the interface between an organization’s reality and a model’s generative capability.
So yes, modern RAG techniques matter.
But in systems built around policy, safety, and compliance, the sequence in which they’re applied matters more than we usually admit. Not because it helps the model answer faster but because it helps the model answer without taking liberties.
If you’re building RAG for policy, compliance, or any domain where fidelity matters more than speed, it’s worth pausing to ask, “What context actually needs to be present?” That question alone can lead to systems that are simpler and ultimately more trustworthy than expected.
It’s also worth noting: These patterns are particularly relevant in environments where data residency or deployment constraints limit the use of cloud-hosted models. That constraint sharpened every design decision, and it’s a story worth exploring separately.
The pace of AI change can feel relentless with tools, processes, and practices evolving almost weekly. We help organizations navigate this landscape with clarity, balancing experimentation with governance, and turning AI’s potential into practical, measurable outcomes. If you’re looking to explore how AI can work inside your organization—not just in theory, but in practice—we’d love to be a partner in that journey. Request an AI briefing.
Key Takeaways
Context engineering determines whether RAG systems act as faithful readers or confident narrators.
In policy and compliance domains, retrieval order matters more than retrieval score.
Chunking decisions shape what the model can understand together, and therefore what it can answer safely.
Similarity-first retrieval works well for discovery, but procedural fidelity requires deterministic context selection.
Classifying intent before retrieval creates more trustworthy outcomes than relying on embeddings alone.
Systems designed around full procedures outperform systems optimized for partial relevance.
Local, open-source LLM deployments amplify the importance of disciplined context construction.
FAQs
What is context engineering in RAG systems?
Context engineering is the deliberate design of what information an LLM sees together in its context window. It focuses on preserving complete meaning, sequence, and dependencies rather than optimizing for similarity scores alone.
Why does retrieval order matter for policy documents?
Policy documents encode responsibility, timelines, and escalation paths across sections. When retrieval order fragments that structure, models produce answers that sound correct while missing critical steps or constraints.
Why do RAG systems hallucinate in compliance scenarios?
They usually do not hallucinate randomly. They infer missing steps when surrounding context is absent. This happens when procedures are split across chunks or retrieved out of sequence.
When should similarity-based retrieval be avoided?
Similarity-based retrieval becomes risky in domains where sequence and completeness matter more than topical relevance, such as safety procedures, regulatory policies, and escalation protocols.
How does classifying before retrieval improve accuracy?
Intent classification allows systems to load entire, relevant sections deterministically. This ensures the model sees complete procedures rather than fragments selected by embedding proximity.
Is this approach compatible with modern RAG architectures?
Yes. It refines modern RAG techniques by sequencing them differently. Vector search becomes a fallback for ambiguity rather than the primary organizing principle.
Does this approach require proprietary models or cloud infrastructure?
No. The system described was built using open-source LLMs running locally, which increased the importance of careful context design and eliminated data exposure risk.
How Applied AI Reduces Cognitive Load and Supports Employee Mental Health
Mary Peake
Some might think mental health in the workplace starts and ends with a meditation app subscription or an Employee Assistance Program (EAP) link. I have been guilty of sharing such solutions in the past with our talent at Robots & Pencils.
Over time, I have come to see how incomplete that framing can be.
Cognitive Load is the Overlooked Driver of Workplace Stress
As I have been growing in my career, and as someone who oversees payroll, benefits, and 401k/RRSP administration for a cross-border team at Robots & Pencils, I am starting to see mental health from a different perspective. I see the cognitive load. The quiet, compounding mental tax created when systems do not talk to each other, processes remain unclear, and routine administrative work slowly becomes a second job.
We live in an era of applied AI, where we are building tools capable of automating what once felt impossible. Yet many employees still experience persistent administrative friction. When a data feed fails, when a vacation request stalls across disconnected platforms, or when an exception requires manual workarounds, the stress that follows is rarely dramatic. It is ambient. It lingers.
It shows up as background noise. Where can I find my paystub? How does my pension match work? Is my family actually covered? These are foundational questions, and when the answers feel uncertain, they pull attention away from the creative and strategic work our teams are here to do. Over time, that uncertainty erodes trust, not just in systems, but in the organization itself.
Where Systems Reliability and Human Care Meet
At Robots & Pencils, we talk about blending the sciences with the humanities. My role often places me directly at that intersection. I act as a human bridge between complex systems and the people who rely on them. Because our internal processes are rarely linear, a personal touch becomes more than a courtesy. It becomes a practical mental health strategy grounded in reliability and clarity.
I have learned that sometimes the most meaningful way I can support the well-being of our team is not by sharing reminders about rest or resilience. It is by reducing the amount of cognitive effort required to navigate everyday work. That might mean using AI tools to build a clearer, more resilient spreadsheet for third-party data uploads, or creating an internal standard operating procedure so critical steps live outside my own memory.
Applied AI Creates the Conditions for Well-Being
By externalizing process knowledge and reducing manual friction, I free up time and attention. That time allows me to personally navigate fragmented systems on behalf of the team, answer payroll questions with confidence, and offer the human service of explanation and reassurance when it matters most.
In that sense, applied AI does not replace care. It creates the conditions for it. When systems are reliable, people can focus. When processes are clear, trust grows. Reliability itself becomes a form of support, and clarity becomes a quiet contributor to mental well-being.
As work becomes more complex, the organizations that thrive will be the ones that design for focus, trust, and human capacity. Applied AI plays a role, not as a replacement for care, but as a way to create the conditions where care can scale. The work begins by asking a simple question: Where could clarity change the experience of work? Request an AI Briefing today.
Key Takeaways
Employee mental health is shaped by everyday systems and processes, not only by wellness benefits.
Cognitive load increases when administrative work becomes fragmented, unclear, or overly manual.
Applied AI helps reduce mental strain by externalizing process knowledge and improving reliability.
Systems that work predictably create trust, which supports focus, creativity, and confidence.
AI creates leverage when it removes friction so people can spend more time on human-centered work.
FAQs
What is cognitive load in the workplace?
Cognitive load refers to the mental effort required to complete tasks and manage information. In the workplace, it often increases when systems are fragmented, processes lack clarity, or employees must hold critical steps in memory to ensure work gets done correctly.
How does applied AI support employee mental health?
Applied AI supports employee mental health by reducing administrative friction. When AI helps organize data, clarify processes, and improve reliability, employees spend less mental energy navigating uncertainty and more time focusing on meaningful work.
Can AI replace human support in HR or operations?
AI does not replace human support. It creates conditions where human care is more effective. By handling repetitive or error-prone tasks, AI frees time and attention for explanation, reassurance, and judgment that require a human presence.
What role do systems play in employee trust?
Reliable systems signal care and competence. When processes work consistently and information is easy to access, employees feel supported and confident that the organization is looking out for them.