

This moment is familiar. A “simple” policy question comes up, and the conversation slows to a halt. Not because the answer is unknowable, but because it’s buried somewhere in a 100-page PDF, inside a binder no one wants to open, on an intranet that technically exists but rarely helps when it matters.
Under time pressure, people do what people always do. They ask around. They rely on memory. They make the best call they can with what they recall.
That’s the situation many organizations quietly operate in. Field teams losing meaningful time every shift just trying to locate procedures. Compliance leaders increasingly uneasy with how often answers came from tribal knowledge. The documents exists. Access technically exists. What’s missing is usable context.
When Policy Knowledge Exists but Usable Context Does Not
The obvious move is to build a RAG (Retrieval-Augmented Generation) assistant.
That’s where the real work begins.
What we didn’t fully appreciate at first was that this wasn’t a retrieval problem. It was a context construction problem.
The challenge wasn’t finding relevant text. It was deciding what the model should be allowed to see together. In hindsight, this had less to do with RAG mechanics and more to do with what we’ve come to think of as context engineering: deliberately designing the context window so the model sees complete, coherent meaning instead of fragments.
Where the “Obvious” Solution Fell Short

We didn’t start naïvely. We explored modern RAG patterns explicitly designed to reduce context loss. Parent–child retrieval, hierarchical and semantic chunking, overlap tuning, and filtered search strategies. These approaches are widely used in production for structured documents, and for good reason.
They did perform better than baseline setups.
But for these policy documents, the same failure mode kept showing up.
Answers were fluent. Confident. Often almost right.
Procedures came back incomplete. Steps appeared out of order. Exact wording, phone numbers, escalation paths, timelines – softened or blurred. And when the model couldn’t see the missing context, it filled the gaps with something plausible.
Why “Almost Right” Answers Are Dangerous in Compliance & Procedural Work
At that point, the issue was no longer retrieval quality.
It was context loss at decision time.

A procedure isn’t just information. It’s a sequence with dependencies. Even when parent documents were pulled in after similarity-based retrieval, the choice of which parent to load was still probabilistic, driven by embedding similarity rather than document structure.
In compliance-heavy environments, “coherent but incomplete” is an uncomfortable place to land.
This became the line we couldn’t ignore:
Chunking isn’t a neutral technical step. It’s a design decision about what context you’re willing to lose and when.
Chunking Is a Design Choice About Risk
Most modern RAG systems correctly recognize that context matters. Parent–child retrieval and hierarchical chunking exist precisely because naïve fragmentation breaks meaning.
What many of these systems still assume, though, is that similarity-first retrieval should remain the primary organizing principle.
Why Similarity-First Retrieval Breaks Policy Logic
For many domains, that’s a reasonable default. For large policy documents, it turned out to be the limiting factor.
Policy documents reflect how institutions think about responsibility and risk. They’re organized categorically. They use deliberate, constrained language like – within 24 hours, contact this number. And their most important procedures often span pages, not paragraphs.
When that structure gets flattened into ranked results, even if parent sections are expanded later – similarity still decides which context the model sees first.
And when surrounding context disappears, the model does what it’s trained to do: it narrates.
Not recklessly. Not maliciously.
Just helpfully.
That was the subtle failure mode we kept encountering – the system becoming a confident narrator when what the situation required was a careful witness.
Naming the Problem Changed the System
Once we framed this as a context engineering problem, the architecture shifted.
Instead of asking, “How do we retrieve the most relevant chunks?” we started asking a different question:
What does the model actually need to see to answer this safely and faithfully?
That reframing moved us away from similarity-first defaults and toward deliberate context construction.
In retrospect, this wasn’t a rejection of modern RAG techniques. It was a refinement of them.
The Design Decisions That Actually Changed Outcomes
Once the problem was named clearly, a small set of design decisions emerged as disproportionately impactful. None of these ideas are novel on their own. What mattered was how they were combined.
Classify First, Then Retrieve
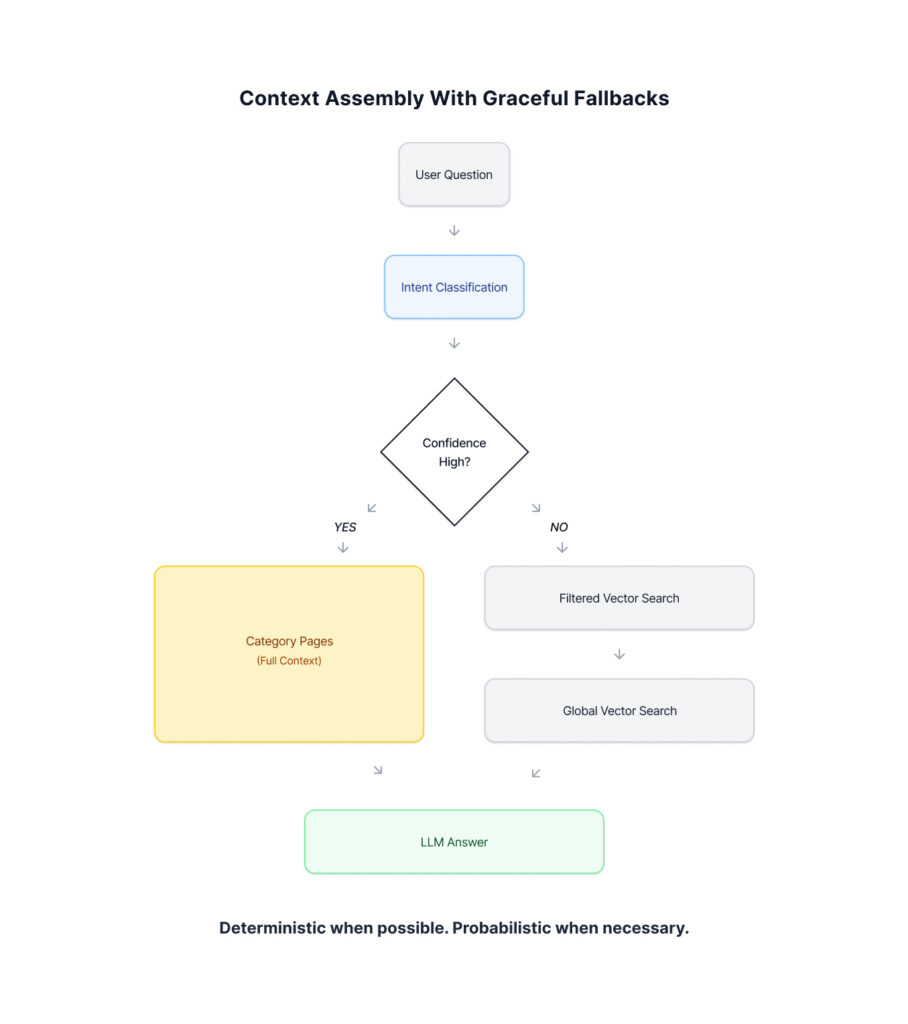
Before touching the vector store, the system classifies what the user is asking about. An LLM determines the query category and confidence level.
When confidence is high, full pages from that category are loaded via metadata lookup – no embedding search required.
When confidence is low, the system falls back to chunk-based vector search, not as the default, but as a safety net for ambiguous or cross-cutting questions.
You can think of this as parent–child retrieval where the parent is selected deterministically by intent, rather than probabilistically by similarity.
Dual Document Architecture
Location-specific documents were separated from company-wide documents, each with its own taxonomy. “What’s the overtime policy?” and “Where’s the emergency exit?” require fundamentally different context.
Domain-Specific Taxonomy
Categories were designed to align with how policy documents are actually authored, not how users phrase questions. Categories were assigned at upload time, not query time, making retrieval deterministic and fast.
Token-Aware Page Loading
Even full pages can exceed context limits. Dynamic loading prioritizes contiguous pages and stops when the token budget is reached. The tradeoff was intentional: complete procedures beat partial matches.
The Big Lesson: Context Is the Real Interface Between Policy and AI Judgment
Context is easy to treat as plumbing – important, but invisible.
In reality, context is the interface between an organization’s reality and a model’s generative capability.
So yes, modern RAG techniques matter.
But in systems built around policy, safety, and compliance, the sequence in which they’re applied matters more than we usually admit. Not because it helps the model answer faster but because it helps the model answer without taking liberties.
If you’re building RAG for policy, compliance, or any domain where fidelity matters more than speed, it’s worth pausing to ask, “What context actually needs to be present?” That question alone can lead to systems that are simpler and ultimately more trustworthy than expected.
It’s also worth noting: These patterns are particularly relevant in environments where data residency or deployment constraints limit the use of cloud-hosted models. That constraint sharpened every design decision, and it’s a story worth exploring separately.
The pace of AI change can feel relentless with tools, processes, and practices evolving almost weekly. We help organizations navigate this landscape with clarity, balancing experimentation with governance, and turning AI’s potential into practical, measurable outcomes. If you’re looking to explore how AI can work inside your organization—not just in theory, but in practice—we’d love to be a partner in that journey. Request an AI briefing.
Key Takeaways
- Context engineering determines whether RAG systems act as faithful readers or confident narrators.
- In policy and compliance domains, retrieval order matters more than retrieval score.
- Chunking decisions shape what the model can understand together, and therefore what it can answer safely.
- Similarity-first retrieval works well for discovery, but procedural fidelity requires deterministic context selection.
- Classifying intent before retrieval creates more trustworthy outcomes than relying on embeddings alone.
- Systems designed around full procedures outperform systems optimized for partial relevance.
- Local, open-source LLM deployments amplify the importance of disciplined context construction.
FAQs
What is context engineering in RAG systems?
Context engineering is the deliberate design of what information an LLM sees together in its context window. It focuses on preserving complete meaning, sequence, and dependencies rather than optimizing for similarity scores alone.
Why does retrieval order matter for policy documents?
Policy documents encode responsibility, timelines, and escalation paths across sections. When retrieval order fragments that structure, models produce answers that sound correct while missing critical steps or constraints.
Why do RAG systems hallucinate in compliance scenarios?
They usually do not hallucinate randomly. They infer missing steps when surrounding context is absent. This happens when procedures are split across chunks or retrieved out of sequence.
When should similarity-based retrieval be avoided?
Similarity-based retrieval becomes risky in domains where sequence and completeness matter more than topical relevance, such as safety procedures, regulatory policies, and escalation protocols.
How does classifying before retrieval improve accuracy?
Intent classification allows systems to load entire, relevant sections deterministically. This ensures the model sees complete procedures rather than fragments selected by embedding proximity.
Is this approach compatible with modern RAG architectures?
Yes. It refines modern RAG techniques by sequencing them differently. Vector search becomes a fallback for ambiguity rather than the primary organizing principle.
Does this approach require proprietary models or cloud infrastructure?
No. The system described was built using open-source LLMs running locally, which increased the importance of careful context design and eliminated data exposure risk.


